Using the upload API
Overview
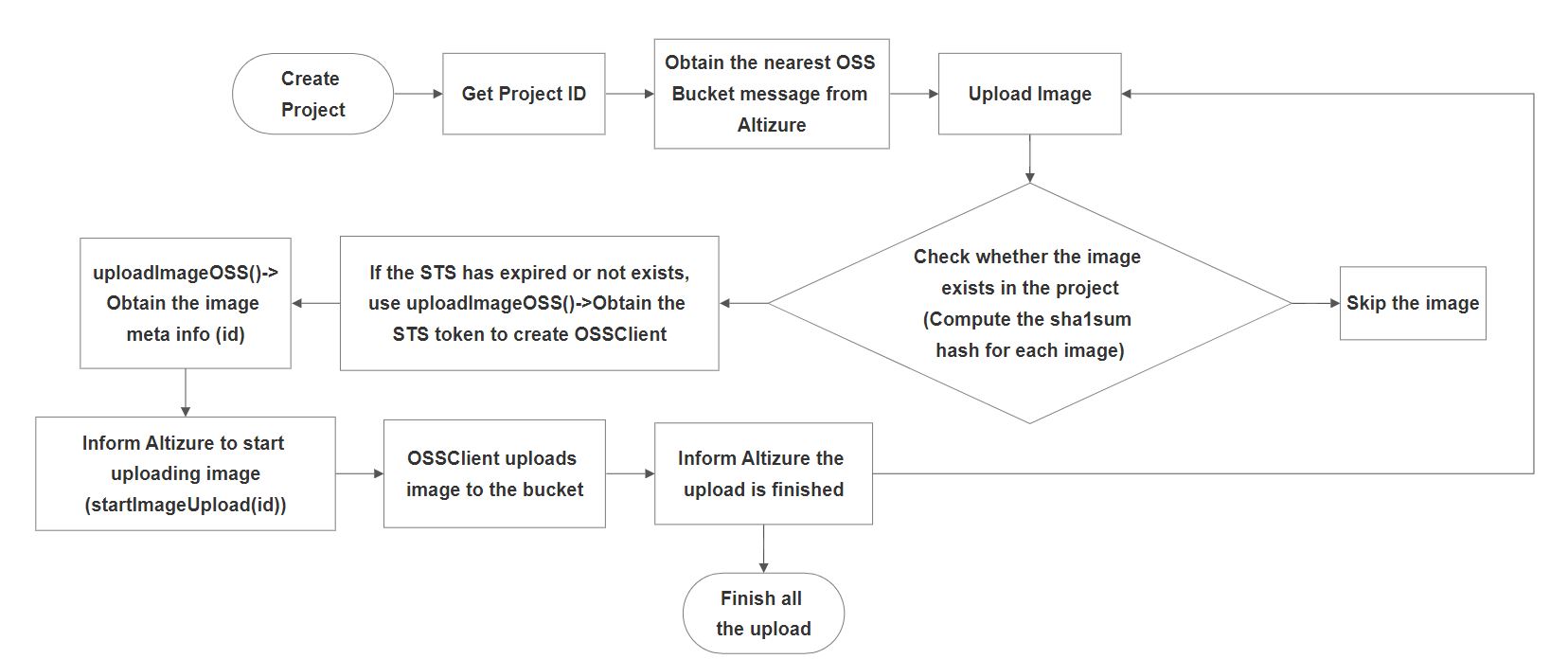
To speed up data transfer, images are uploaded directly from clients to Amazon or Aliyun. Your images are protected securely. Others could not read or modify your images. That is why you need to obtain the authorizations from our api. As filename is the only identifier in the buckets, the image is required to be uploaded to a specific url (S3) or prefix (OSS) so that Altizure knows which image is which.
1. Choose bucket
Choose one of the fastest S3 or OSS buckets. This is largely correlated to your network zone with the edge-points.
You may simply query getGeoIPInfo.nearestBuckets for hints for auto selecting the best edge for your clients.
2. Compute image checksum
Compute the sha1sum hash for each image.
Before each upload, check if the current image has already been uploaded by calling the mutation hasImage(pid, checksum).
If it is not, proceed to the next step. Otherwise, skip to the next image.
3. Upload to OSS
If an OSS bucket is chosen, obtain STS and the related meta image info (e.g. id and hashed filename) by calling mutation uploadImageOSS(pid, bucket, filename, type, checksum). STS is a temporary (1 hour) security token for the write only permission on the /pid prefix.
If it has expired, renew with the same mutation. Otherwise, only request the image gql fragment from the result, and re-use the same STS for performance reason. As signing from Aliyun is slow, one should not sign a new STS for each image. If the Wrapper in Aliyun OSS Javascript SDK is used, please do not recreate new wrappers before STS expires to avoid an error about too many sockets.
Given the STS, images could be uploaded via any compatible protocol or library to OSS. It is required to upload with the specific hashed filename according to the image info returned from the uploadImageOSS mutation. Specifically, it is required to be put to the path ${pid}/${image.filename} inside the bucket.
In order to keep track of the state, just before an image is uploaded, call mutation startImageUpload(id) to signal the start of the process. When the upload is done, call mutation doneImageUpload(id).
flow chart:
- Minimal Example with Javascript in Browser: https://github.com/altizure/oss-upload-minimal
4. Upload to S3
If a S3 bucket is chosen, uploading is much simpler.
For each image, call the mutation uploadImageS3(pid, bucket, filename, type, checksum) to obtain a temporary (3 hours) signed url and the related meta image info. You are recommended to get the image.id from this mutation because it is required for the next mutation.
Given the signed url, use the standard HTTP put to put the file to this url with Content-type: JPEG or other formats accordingly.
Just before each upload, it is required to call mutation startImageUpload(id). id is image.id, which is fetched previously. There is no need to signal the end of uploading.
- Minimal Example with NodeJS: https://github.com/altizure/s3-upload-minimal-example
5. Wait for image processing
Uploaded images will be copied, verified and processed. Eventually, the image state will become either Ready or Invalid.
If the total count of Ready matches the desired number, you may call mutation startReconstructionWithError(id, options) to start the reconstruction. Otherwise, you may consider re-uploading any outstanding image as indicated by the mutation hasImage.
If you do not concern about a few number of missing images and want to start the reconstruction immediately once all the images are ready, you could call mutation preStartReconstruction(id, options).
Next
After images are processed. you could start a reconstruction.
Example
- OSS: https://github.com/altizure/oss-upload-minimal
- S3: https://github.com/altizure/s3-upload-minimal-example
Learn more
Last modified at Wed Jan 08 2020 09:31:35 GMT+0000 (Coordinated Universal Time)